Architecture · BMK-02
The whole stack at a glance.
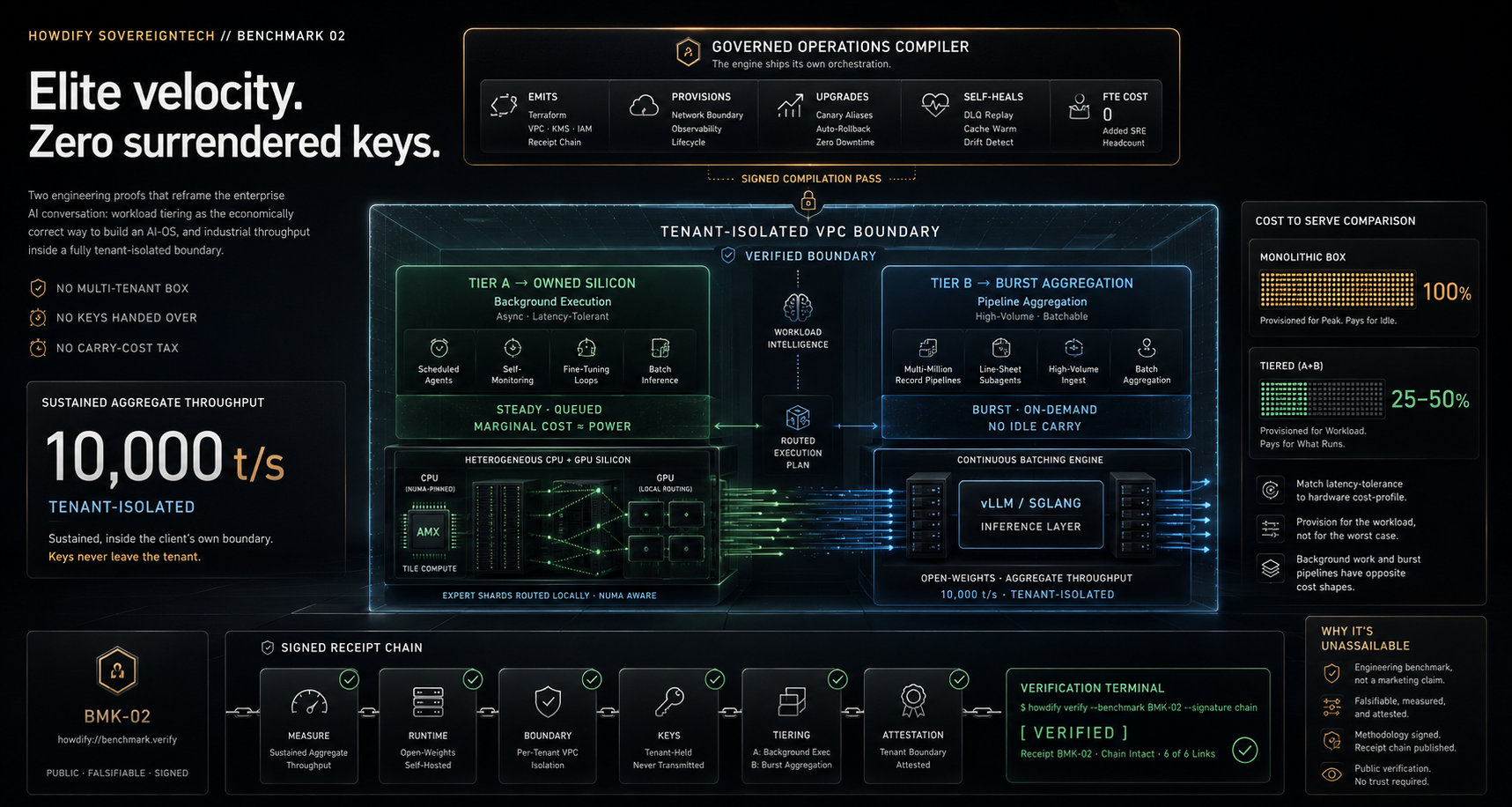
Tier A and Tier B inside one verified VPC boundary, routed by workload intelligence, attested by a signed receipt chain.
 ↗ Tap to expand
↗ Tap to expand
Two engineering proofs that reframe the enterprise AI conversation: workload tiering as the economically correct way to build an AI-OS, and industrial throughput inside a fully tenant-isolated boundary. No multi-tenant box. No keys handed over. No carry-cost tax.
Tier A and Tier B inside one verified VPC boundary, routed by workload intelligence, attested by a signed receipt chain.
↗ Tap to expand
An engineering benchmark, not a marketing claim. Each proof is falsifiable, measured, and attested with a signed receipt chain.
The monolithic always-on endpoint bills around the clock for work that is bursty or batchable. We prove that workload tiering, separating background execution from high-volume pipeline aggregation, lets a client match each workload to the cheapest silicon that satisfies it, including hardware already sitting in their server room.
The hyperscaler premise is that scale requires renting their multi-tenant box. We refute it. An enterprise does not surrender its data boundary or its encryption keys to reach industrial velocity. A tenant-isolated environment sustains a 10k t/s aggregate throughput on a modest open-weights footprint.
Match latency-tolerance to hardware cost-profile. Provision for the workload, not for the worst case.
Tier A does not require pristine high-VRAM GPU clusters. The execution layer is architected for heterogeneous CPU-GPU environments: expert shards are NUMA-pinned and routed locally, with AMX (Advanced Matrix Extensions) tile operations carrying the dense math on the host CPU. Standard, CPU-heavy enterprise iron becomes a cost-effective batch inference engine. Scheduled agents, self-monitoring, fine-tuning loops, and batch inference all queue here.
The heavy ingest and aggregation lanes: multi-million-record pipelines, line-sheet subagents. High volume, but it batches. So it bursts on demand instead of holding 24/7 capacity that idles most of the day.
Aggregate, batched, concurrent. Sustained inside a single tenant's isolated boundary.
The number is credible because it's the right kind of number: aggregate throughput from continuous batching, not single-stream latency. What makes it matter is where it runs. Inside the tenant's own boundary, with the encryption keys never leaving.
Industrial scale used to be the hyperscaler's leverage. It isn't anymore.
Sovereignty without an SRE payroll tax. Howdify is a Governed Operations Compiler, not just an inference engine.
Howdify compiles and orchestrates its own tenant-isolated sandboxes directly into your existing infrastructure via signed Terraform plans. Provisioning, key wiring, network boundary, observability, and lifecycle are all emitted from the same signed compilation pass that ships the inference layer. You get total data sovereignty without adding a single hour of maintenance overhead to your infrastructure team.
Three premises the industry sells as law. None of them survive the benchmark.
Background work and burst pipelines have opposite cost shapes. Sizing one endpoint for both means paying peak rates for idle time.
Continuous batching on open weights reaches industrial throughput on hardware you control. The multi-tenant box was never required.
Tenant isolation and elite velocity coexist. The trade-off everyone assumes was an artifact of the hosted model, not physics.
A number with no methodology is assailable by definition. So we sign the methodology and publish it.
If sovereignty no longer costs performance and tiering no longer costs scale, what's the actual reason your AI-OS still lives in someone else's tenant?