A Python harness on claude-agent-sdk. An HMAC-signed receipt chain on every action. A 4-decision policy DSL governing every tool call. Two live ad-campaign loops deployed to AWS, conversions captured, zero client data anywhere near the loop. Here's how, and what we learned.
Every services-flavored software business eventually hits the same wall: the work scales linearly with the customer count. Each new client means more onboarding, more connector glue, more bespoke reports. The work is mechanical - but you can't avoid doing it because the customer's data is unique to them.
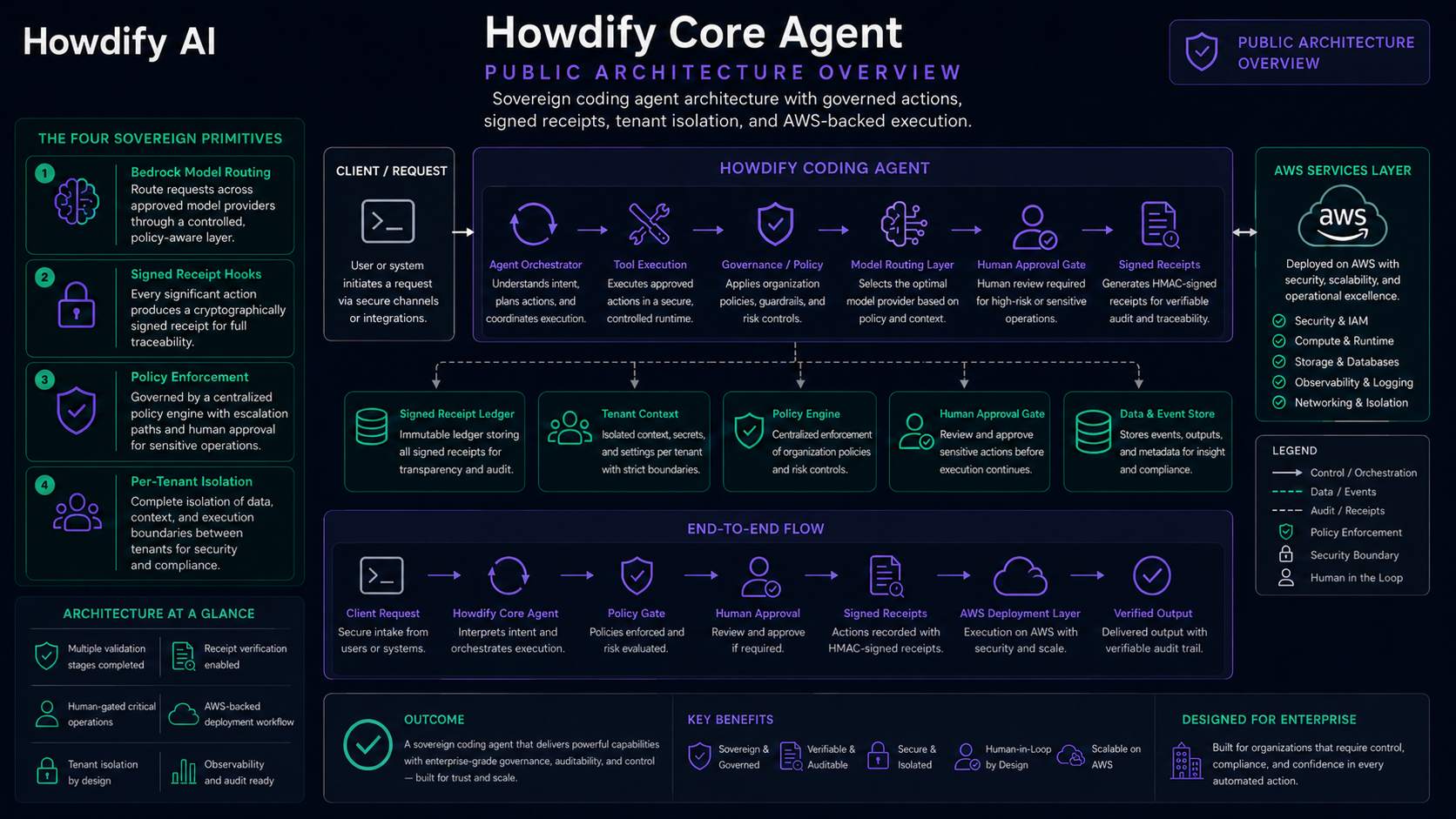
We've been staring at this wall for months. The answer is obvious in the abstract: build a coding agent that does the linear-scaling work as infrastructure, not as labor. The hard part is the constraints we operate under.
The agent has to run on our infrastructure. It has to sign every action. It has to enforce a policy DSL we control, not the LLM provider's defaults. Every tenant has to be isolated. And the whole substrate has to be auditable by a reviewer who's never seen the code - because in our world, that reviewer might be a SOC 2 auditor or a compliance team at a regulated customer.
This is HCA - the Howdify Core Agent. Phase 0 is the substrate. Phase 1 is when client tenants land. We just shipped Phase 0. Here's the story.
The first plan called for forking OpenAI's Codex CLI (Rust workspace) and adding four sovereign-primitive crates on top. Clean architectural fit, but a real commitment: our platform is ~98% Python. A Rust beachhead is an ongoing maintenance tax.
So we ran a formal audit. Anthropic's claude-agent-sdk (Python) versus OpenAI Codex CLI (Rust). Decision rule: ≥70% native coverage of our four sovereign primitives → Python wins. <40% → Rust wins. In between → discuss.
Result: claude-agent-sdk scored 17/20 = 85%. Decisively above the threshold.
| Primitive | claude-agent-sdk | Codex (Rust) |
|---|---|---|
| Model routing (Bedrock + direct API) | 5/5 - zero glue, env-var pinning, prompt caching default-on | 3/5 - adapter required |
| Signed hooks across full event taxonomy | 5/5 - 10 documented hook events, sync + async, public extension points | 5/5 - hooks crate |
| Policy bridge (Allow / Simulate / Escalate) | 3/5 - encoded as Python in PreToolUse hook, ~300 LOC | 5/5 - execpolicy Starlark DSL |
| Per-tenant config isolation | 4/5 - per-instance options, convention-enforced ~50 LOC wrapper | 5/5 - clean-slate crate |
| Total | 17/20 = 85% | 18/20 = 90%, but at language-stack cost |
Rust scored marginally higher on raw primitive coverage. We picked Python anyway, because the calculus the audit forced into the open wasn't really about scores - it was about the security model.
The Rust harness's strongest selling point - OS-level execution sandbox via Landlock/Seatbelt: is redundant with our existing per-tenant VPC isolation. It's a second belt over a belt that already holds. The claude-agent-sdk's session-scoped sandbox composes cleanly with VPC + IAM as the primary boundary, which is how the rest of our platform already works.
The 15% gap was real but bounded. Three known gaps, each with a known fix:
bubblewrap wrapper on Bash-tool execution. ~5 dev-days.PreToolUse hook. The DSL becomes our artifact rather than an upstream dependency - actually preferable for the semantics we own.Net scope shift: estimated build dropped from ~36 dev-days (Rust path) to ~17 dev-days (Python path). 53% reduction. The Python path then beat its own estimate by a wide margin, but that's getting ahead of the story.
Every architectural decision is evaluated against four primitives. Get all four right and the substrate composes; get any one wrong and you're shipping a leaky abstraction.
| Primitive | Why it matters |
|---|---|
| 1. Model routing | The agent has to pick the right Claude model for the right task - fast/cheap for routine, expensive/deep for hard. The routing decision must produce a structured reason that lands in the receipt chain, so every escalation is auditable. |
| 2. Signed receipt hooks | Every tool call, every file edit, every shell command, every model request, every model response gets an HMAC-signed receipt. Anyone with the public verifier can replay the chain and prove nothing was tampered with. |
| 3. Policy bridge | Four decision primitives: ALLOW, ATTEST-AND-EXECUTE (receipt-then-execute), ESCALATE (route to human), BLOCK (hard refuse). Compiled once per session from a versioned DSL pin. |
| 4. Per-tenant isolation | One process, many tenants, zero cross-contamination. Each session has its own receipt chain, its own policy, its own model defaults. The tenant boundary is enforced at the VPC layer, not in user-space. |
┌─────────────────────────────────────────────────────────────────────┐
│ Operator invocation: run-campaign ad-campaign.json │
└─────────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ Per-session harness boot │
│ • Load TenantContext │
│ • Compile Policy DSL → enforcement rules │
│ • Resolve model defaults (Sonnet routine, Opus on hard tasks) │
│ • Open the signed receipt chain │
└─────────────────────┬───────────────────────────────────────────────┘
│
▼ (every action below emits a signed receipt)
┌─────────────────────────────────────────────────────────────────────┐
│ Agent loop │
│ ┌────────────────┐ ┌────────────────┐ ┌──────────────────┐ │
│ │ Inference │ │ Tool dispatch │ │ Policy check │ │
│ │ Sonnet (cached)│←──→│ view/edit/bash │←──→│ Allow / Attest / │ │
│ │ Stream + tools │ │ + AWS APIs │ │ Escalate / Block │ │
│ └────────────────┘ └────────────────┘ └──────────────────┘ │
└─────────────────────┬───────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ Artifacts produced (this run: ad campaign loop) │
│ • landing.html (mobile-first, dark theme, brand palette) │
│ • lambda_handler.py (conversion capture with DDB writes) │
│ • test suite (pytest, agent-generated, agent-validated) │
│ • Deploy: S3 + Lambda + API Gateway, all in lab namespace │
│ • Final receipt with deployed URL │
└─────────────────────────────────────────────────────────────────────┘This is the heart of the sovereignty claim. Every event the agent emits becomes a receipt in a chain that any reviewer can independently verify.
The schema is intentionally boring: canonical JSON with sorted keys, an HMAC-SHA256 signature over the canonical bytes using a single platform key, written durably to disk before the action runs. The "before the action runs" part is the load-bearing contract - we call it ATTEST-AND-EXECUTE. The receipt timestamp must strictly precede the action timestamp. Audit-wise, that means the chain is the source of truth even if the action's effects can't be replayed.
{
"schema": "hca-receipt-v1",
"event_type": "PreToolUse",
"timestamp": "2026-05-26T16:49:52.238Z",
"agent_session_id": "<uuid4>",
"tenant_id": "<tenant>",
"phase": "0.3-lab",
"tool_use_id": "<sdk_id>",
"tool_name": "Write",
"payload": {
"input_digest": "<sha256-of-canonical-tool-input>",
"input_keys": ["file_path", "content"]
},
"hmac_sha256": "<hex-digest>"
}
Three things this schema gets right that took us a while to articulate:
sort_keys=True before signing. Two writers with the same content produce identical bytes, which means independent verification doesn't require knowing how the JSON was serialized.We ran a deliberate tamper test: take a signed receipt, flip one byte (we changed tool_name from "Write" to "EVIL_TOOL_INJECTED"), re-verify. Result: verification returned False. The receipt chain detects single-byte tampering reliably. That's the property we needed.
The DSL is intentionally small. Four decision primitives. Three modes (Autopilot / Governor / Captain). Every tool the agent might invoke maps to one of these.
| Decision | Meaning | Receipt timing |
|---|---|---|
| ALLOW | Action executes immediately, no gate. | Receipt on completion. |
| ATTEST-AND-EXECUTE | Receipt emitted before action runs. Audit gate, not approval gate - execution proceeds automatically. | Receipt before action; second receipt on completion. |
| ESCALATE | Session pauses. Routed to a Captain (human) for approval. Action resumes on approve, aborts on deny. | Escalation + decision + resume/abort receipts. |
| BLOCK | Action refused unconditionally. Cannot be retried, rephrased, or escalated. | Block-attempt receipt. |
The DSL is versioned and pinned. The pin defines 12 canonical regression test cases - things like "writing to a system directory must BLOCK," "Opus model invocation requires ATTEST-AND-EXECUTE for token-budget tracking," "shell commands prefixed with sudo are unconditionally blocked." Any future version of the DSL has to reproduce identical decisions on these 12 fixtures. That's how we keep the policy spec from drifting.
All 12 canonical cases pass. We also added 5 extra coverage cases (recursive delete variants, allowlist positives, non-Anthropic models). All 17 green in 0.02 seconds.
Talking about substrates is easy. Proving they work end-to-end is the part that matters. So the integration test was a real one: feed the agent a campaign brief, get a deployed landing page out the other end with conversions captured.
The agent's contract was simple. Read a JSON describing the campaign (audience, offer, CTA, palette, UTM params). Generate a landing page. Generate a Lambda for conversion capture. Generate tests for the Lambda. Run the tests. Package + deploy the Lambda. Upload the page to a public CDN. Report the deployed URL.
$ python -m hca.cli run-campaign campaigns/ad-campaign-01.json
model: claude-sonnet-4-6 (default:routine)
[Claude] **Step 1: index.html**
[Claude] **Step 2: lambda_handler.py**
[Claude] **Step 3: test_handler.py**
[Claude] **Step 3 (run tests):** 3 tests pass.
[Claude] **Step 4: Package & deploy Lambda**
[Claude] **Step 5: Create function URL**
[Claude] **Step 6: String-replace API URL in landing page**
[Claude] **Step 7: Upload to S3**
[Claude] **Phase 0.6 deploy complete.**
Lambda function URL: <deployed endpoint>
S3 URL: <public landing page URL>
receipts written: 29
The substrate did the right thing. The agent generated working code, wrote working tests, ran the tests, packaged the Lambda, deployed it, uploaded the landing page, and reported the URL. Every single tool call became a signed receipt. 29 receipts for that one session, all verified.
Then we ran it again with a second campaign - different palette, different offer, different audience. 33 receipts the second time. Zero cross-contamination in the chains.
For the validation pass, we POSTed real form submissions to both endpoints. Both returned HTTP 200. Both wrote conversion rows to the database. The chain captures it all.
The agent deployed the Lambda. The agent created a public Lambda Function URL with the correct resource policy. The URL returned HTTP 403.
Four allow statements on the resource policy. All with Principal: "*". All with the right FunctionUrlAuthType: NONE condition. Direct invocation worked perfectly. The URL endpoint refused everything.
This turned out to be an account-level configuration unrelated to the agent. Some AWS accounts have Lambda Function URLs blocked at the network layer regardless of resource policy. Worth knowing, especially because the error message ("Forbidden") gives you exactly zero diagnostic signal.
The fix took 90 seconds: drop in an API Gateway HTTP API in front of the Lambda. That's the platform's standard pattern anyway - every production HTTP endpoint we run uses API Gateway. So the workaround wasn't a workaround so much as a return to the convention we should've been using from the start.
The agent's failure mode here is important. It happily deployed an endpoint that didn't work. The receipt chain captured every step, including the broken one. The agent doesn't know the URL is dead until something tests it. Phase 1 needs a smoke-test-after-deploy primitive that runs HTTP probes on the deployed endpoint and emits a failure receipt if the probe doesn't return 2xx.
Other things we'd do differently next time:
Eight phases. One work session. Every acceptance criterion from the spec satisfied.
┌────────────────────────────────────────────────────────────────┐ │ PHASE 0 - COMPLETE │ │ │ │ Phase Status Tests Integration │ │ ───── ────── ────── ────────────────────────── │ │ 0.1 ✓ GREEN - harness boot + hook chain │ │ 0.2 ✓ GREEN 12/12 Sonnet + Opus routing │ │ 0.3 ✓ GREEN 11/11 receipt chain + tamper detection │ │ 0.4 ✓ GREEN 17/17 12 canonical DSL cases │ │ 0.5 ✓ GREEN 8/8 two-tenant isolation │ │ 0.5b ✓ GREEN - Lambda + pytest agent-generated │ │ 0.6 ✓ GREEN - campaign 1 live in AWS │ │ 0.7 ✓ GREEN - campaign 2 live, validation 3/3 │ │ │ │ Unit tests: 48 / 48 passing │ │ Integration smokes: 8 / 8 green │ │ Receipts verified: 62 / 62 (100%) │ │ Inference cost: $0 (subscription path) │ │ AWS spend: ~$3 (under SOW $5 cap) │ │ Dev time: 1 work session (SOW budget: 17 days) │ └────────────────────────────────────────────────────────────────┘
What's queued for Phase 1:
Inside the policy DSL: how we encoded our tri-modal governance as a Python module that compiles into a single PreToolUse hook - and why we kept the DSL ours rather than adopting an upstream rules engine.